Problem 1
 首先对
首先对
则
故
由于
这里的量级分析来自第一切比雪夫函数的结论
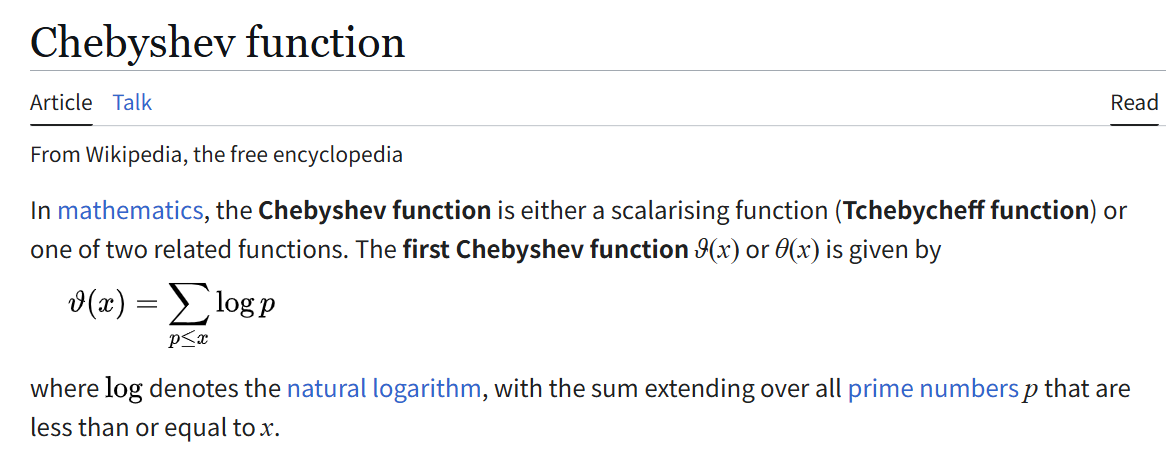

因此一方面,如果对
另一方面,如果
算法即
Problem 2
 由题有
由题有
故
由于
因此只需要尝试
对于每一种可疑的
即
的两个根
使用求根公式求解后,若两个根均为整质数即可判断分解成功,因此整体复杂度为
Problem 3
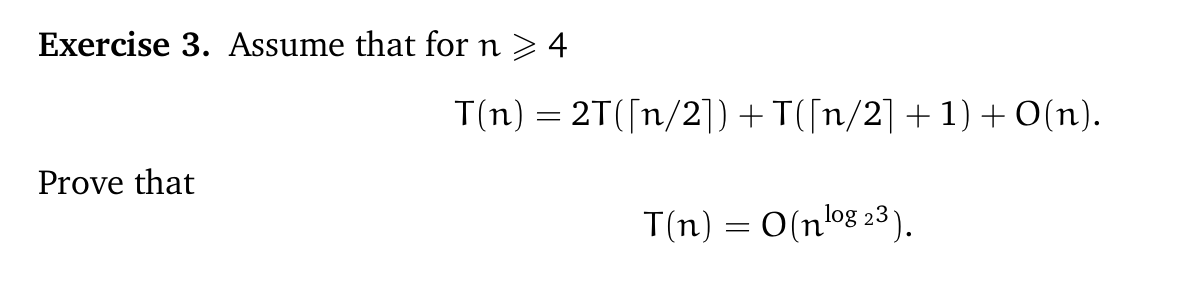 记
记
另设原式中
假设对于所有
则代入原递归式(为书写方便没有考虑取整的影响)得:
又因为
代入上式得:
由拉格朗日中值定理,对函数
故:
要使
也成立,只需保证多余的项小于等于零即可,即:
由于
综上,由数学归纳法得证
Problem 4
 考虑
考虑
故直接二分判断即可
答案即
Problem 5

Task 1

根据题目定义,算法无法直接使用数组的值,对数组进行 query 当且仅当根据数组值之间的序关系对
Task 2
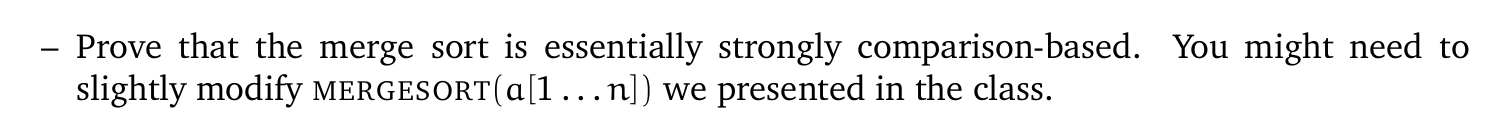 在课上,
在课上, 区别在于没有使用索引而是直接用了
区别在于没有使用索引而是直接用了
则此时用到
Task 3
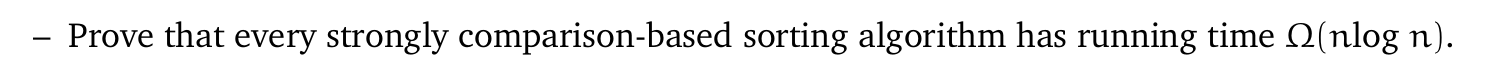 这种 sorting 本质上是一个 decision tree 结构,而每次 compare 只会得到一个二分类,因此 decision tree 是一个二叉树。而这个树需要能遍历所有结果,每种结果即一个
这种 sorting 本质上是一个 decision tree 结构,而每次 compare 只会得到一个二分类,因此 decision tree 是一个二叉树。而这个树需要能遍历所有结果,每种结果即一个
由
因此得到
Task 4
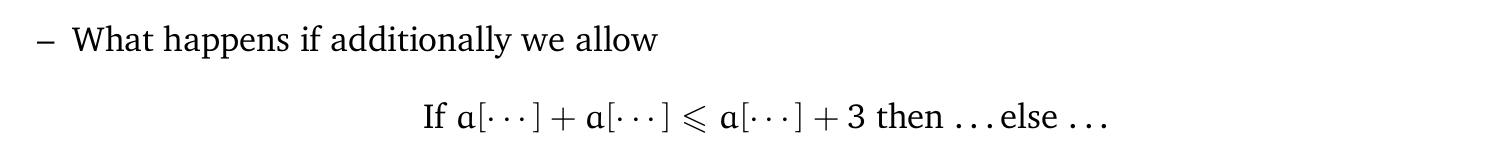 一方面,这个运算是线性(
一方面,这个运算是线性(
Problem 6
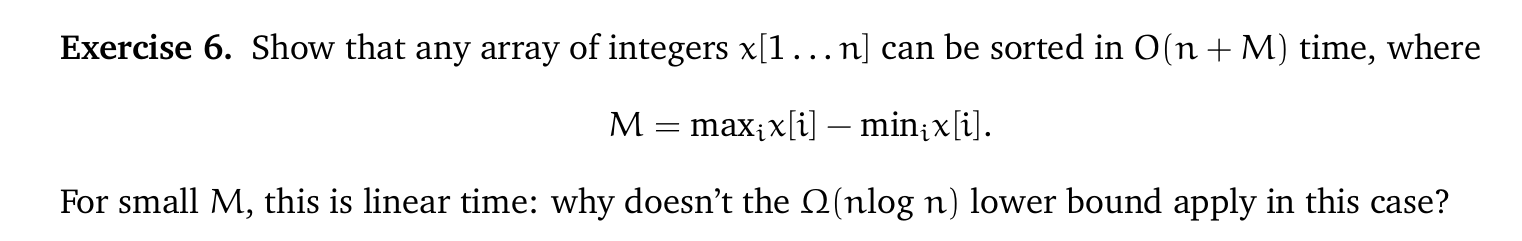
这其实即计数排序的原理
- 对
到 遍历,得到 和 ,也即得到了 - 准备
到 共 个 bucket - 再次从
到 遍历,把每个元素的索引值 放入 bucket 中 - 从 bucket
遍历到 ,按顺序将其中的元素索引输出为
复杂度为