图的基本性质和用邻接矩阵 / 邻接表的表示这里略
无向图中的 DFS
对于图,一个自然的问题是:从  设计如上的算法,容易知道其能够遍历所有 reachable point
设计如上的算法,容易知道其能够遍历所有 reachable point
这一过程将边分为两类
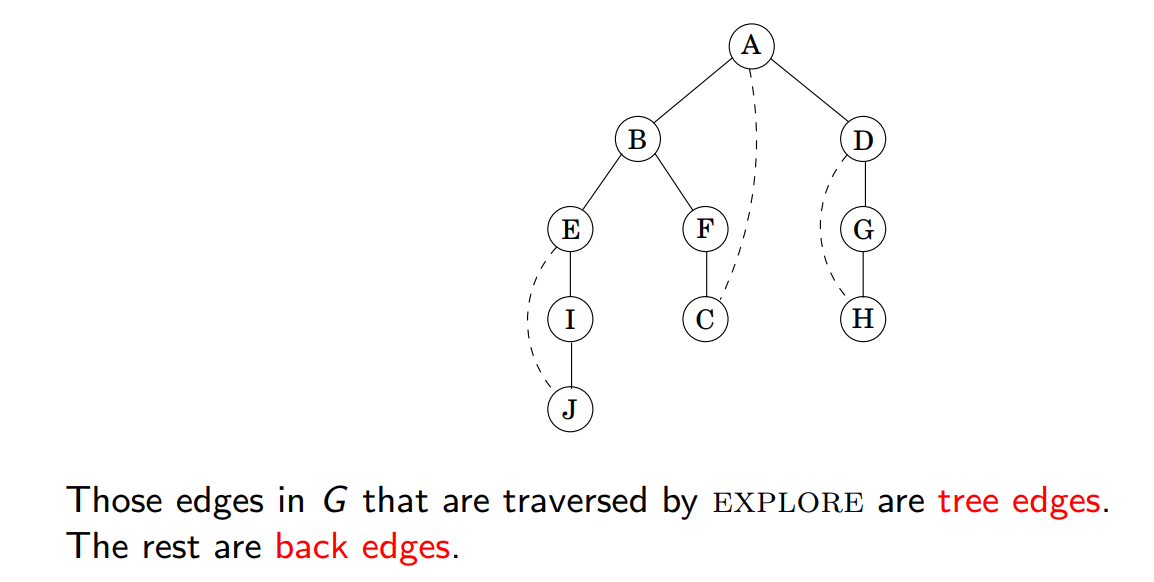
从一个点的遍历发展出 DFS 算法:

DFS 的时间复杂度:

上面的算法引出连通性和连通分量的定义

另外,DFS 中还有一个 “栈关系”:考虑在 explore 的过程中维护时间戳
 那么
那么
有向图中的 DFS
首先我们关注 DFS 中边的类型,DFS 生成了搜索树(森林),并在其中定义了 root, parent & child, ancestor & descendent 的关系,遂可以根据这些关系定义边的类型
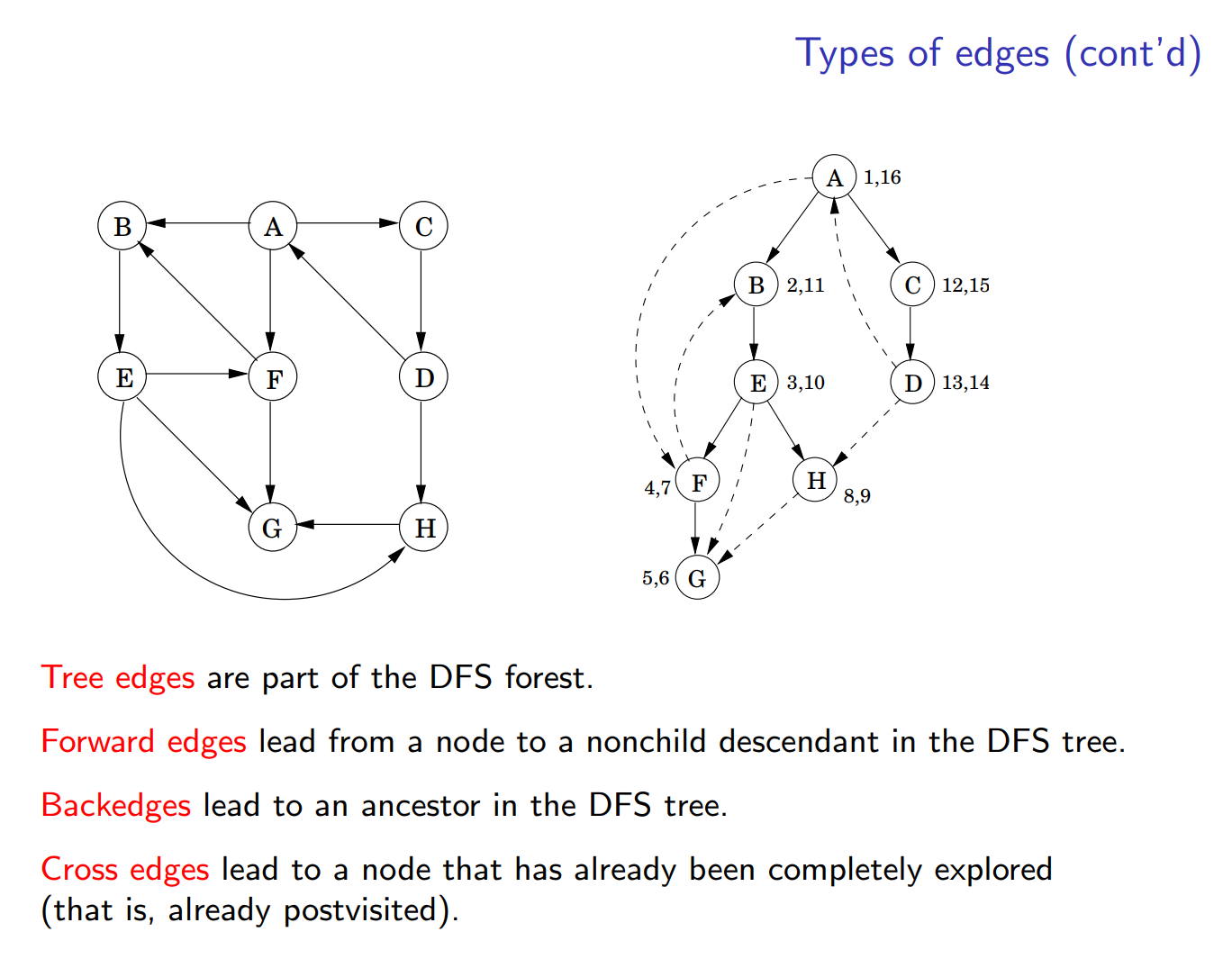
forward 和 cross 的区别:


这个顺序还是比较重要的
从 edge type 引出循环的一个判断方式:一个有向图有循环,当且仅当 DFS 出现 back edge
没有循环的有向图就是 DAG (Directed Acyclic Graph)
我们常说拓扑排序:每个边的终点总比起点的编号大,在 DAG 中一定可以实现
 只需要使用 post number 反向排序即可。既然可以作这样的排序,就有了 sink 和 source (汇与源)的定义,分别是 post number 最小和最大的节点,每个 dag 中都必然有至少一个 sink 和 source
只需要使用 post number 反向排序即可。既然可以作这样的排序,就有了 sink 和 source (汇与源)的定义,分别是 post number 最小和最大的节点,每个 dag 中都必然有至少一个 sink 和 source
强连通分量
有向图中的连通性定义为两个方向都可以连线,在这一定义下,有向图被分为若干个强联通分量,易知任何有向图都是其强连通分量的 DAG(Metagraph)
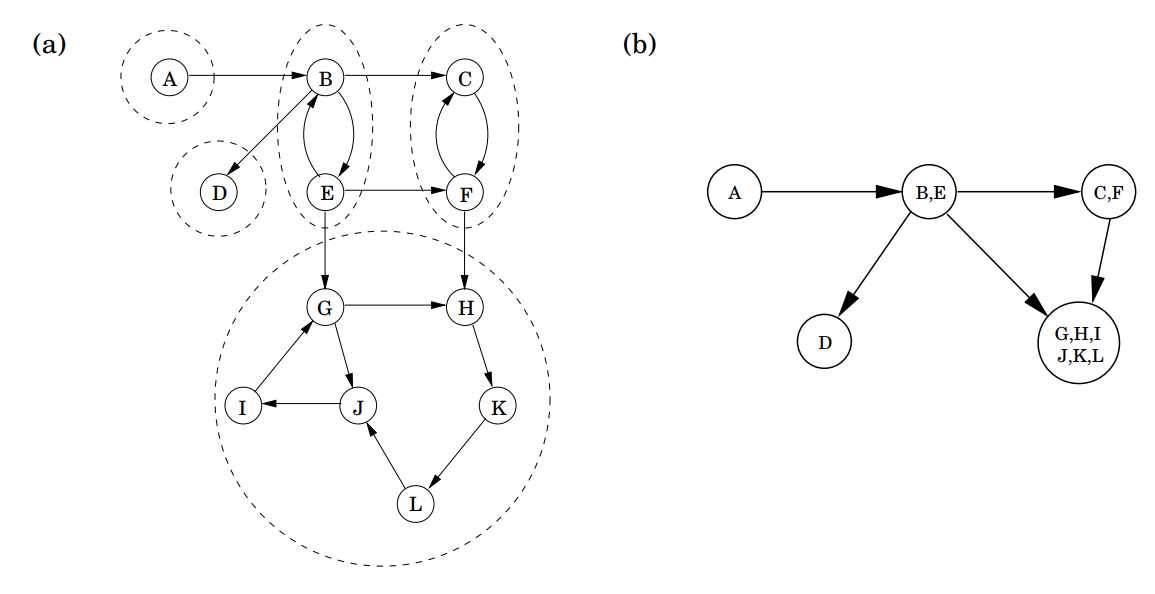 一个自然而然的问题是:如何(按顺序)求得一个图中的各个强连通分量?
一个自然而然的问题是:如何(按顺序)求得一个图中的各个强连通分量?
寻找强连通分量的高效算法:Kosaraju 算法
首先,对于一个特定的 node,如果他在汇点强连通分量中,用前面的 Explore 可以获得它所在的连通分量(因为没有到其他地方的出边)
 所以就出现了
所以就出现了
- 怎么找汇点
- 剥掉这个汇点之后怎么继续 两个问题
对于 DFS,有 Lemma: 对于连通分量
于是把图 reverse 过来变为
 这是一个线性算法
这是一个线性算法